Vector Search from Scratch: Building a FAQ Chatbot
You might have wondered: how does Google know to show you exactly what you need even when you type something slightly different?
Meanwhile, your SQL queries return null when even one word is off.
The answer is Vector search.
You might have used it before when building RAG systems or working with AI tools, but do you actually know how it works?
"Semantics" is all about meaning and context — and here you'll learn how to use vectors to encode them in a way that computers can understand so we can make the best use of it.
In this guide, we'll build a fully functional vector search system from scratch (mostly lol), and by the end, we'll hook it up to a chatbot for RAG.
What You'll Build
By the end of this guide, you'll have:
- A vector search engine that understands meaning
- An FAQ chatbot powered by vector embeddings
- A working RAG (Retrieval-Augmented Generation) system
- Deep understanding of how it all works
Although we'll build our system with SQLite, the patterns, architecture, and design principles you'll learn here are not SQLite-specific. They apply to any vector search system you want to build — whether you later move to Postgres with pgvector, specialized vector databases, or even in-memory solutions.
SQLite is a solid choice for this because it has such a low resource footprint and negligible setup cost. It exists on most devices, so that's a plus if you ever want to deploy such an app.
Who This Guide Is For
This guide assumes you already have:
- Basic programming skills in any language
- Some familiarity with databases (SQL basics)
- Curiosity about how AI search works
The code is in Rust. You can follow the concepts without knowing Rust — but to implement along with the examples you'll need basic Rust familiarity, particularly around structs, traits, and serialization with Serde. The Rust Book is the best place to get up to speed.
Setup
git clone https://github.com/olorikendrick/vector-search-with-rust-and-sqlite
cd vector-search-with-rust-and-sqlite/embeddings
Each chapter may introduce breaking changes. To follow along cleanly, we encourage you to branch per chapter:
git checkout -b chapter-2
cargo run
Optionally replace faq.txt with your own FAQ file before running.
Chapters
Chapter 1: Where Traditional Queries Fail
We explore the limits of traditional SQL and what we can use in its place.
Chapter 2: Building Vector Search
Generate embeddings, store them in SQLite, calculate cosine similarity,
and search.
Chapter 3: Refactoring
Clean up the codebase and
add proper error handling.
Chapter 4: The FAQ Chatbot (coming soon)
Hook it all up to build a complete RAG system.
Any support, contributions, or corrections are appreciated — it keeps me going.
If you find it helpful, star and share!
Chapter 1
Where Traditional Queries Fail
Picture this: your dog just birthed a cute litter of say 5 puppies.
Now let's assume you have no other pets.
If I asked you: "how many pets do you have?", you would naturally say 6. If I asked you: "how many dogs do you have?", you would of course still say 6.
Now I asked slightly similar questions, but you were able to parse the question and answer it correctly.
If you were querying a database for the same answer you would write something to this effect:
SELECT * FROM animals WHERE type = 'pet';
or
SELECT * FROM pets WHERE type = 'dog';
Depending on how you designed your database, your query might yield your desired result.
But we're already running into some common problems. Chief of them is that we need to design our tables and queries to accurately represent relationships between data — not a small feat in itself. For that we need structured data.
Bear in mind that most everyday data is unstructured:
- "I have 2 Rottweilers"
- "I have 3 Cats"
- "I have 3 Tom cats"
- "I have a pet parrot"
- "I have a pet bird"
To us humans, all the above questions obviously have high "similarity".
But in a database there's no implicit similarity between them — it treats each piece of data as an isolated point — unless we make any such relationship explicit somehow. That leads us to the most important issue: encoding such "similarities" to enable computers to process them.
Vector Search
Vectors provide a comprehensive mathematical encoding of the similarities between such unstructured data.
In its simplest form, a vector is any quantity that has both magnitude and direction.
Visualize the diagram in the image below.
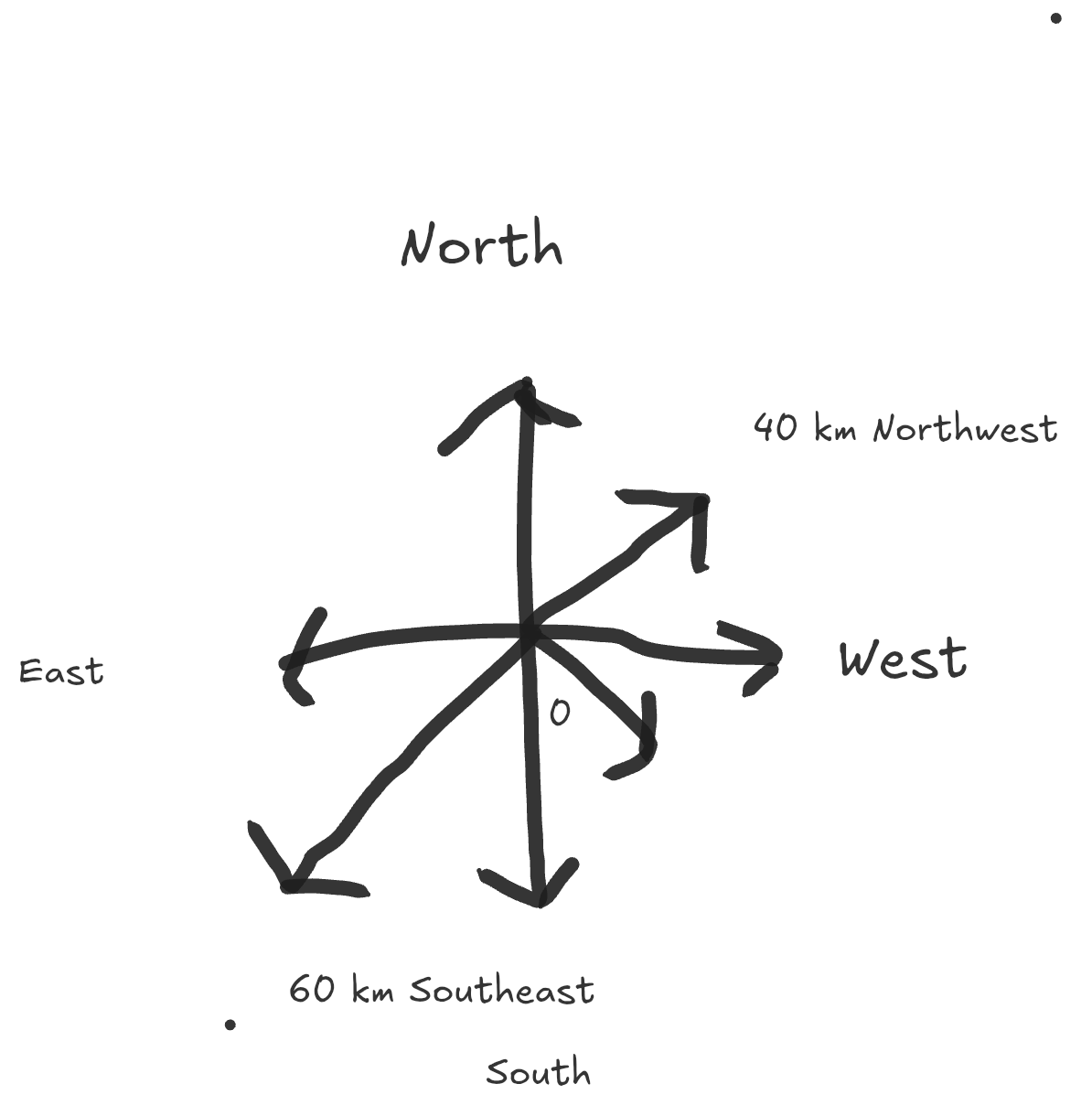
Imagine you're standing at the origin (the center point marked "0").
I could tell you to move 60 km, but that is incomplete — 60km where? you ask.
You need both pieces of information:
- Magnitude: 60 km (how far)
- Direction: Northwest (which way)
So the complete instruction is: "Move 60km Northwest" or "Move 40km Southeast" or "Move 40km North."
Why Direction Matters
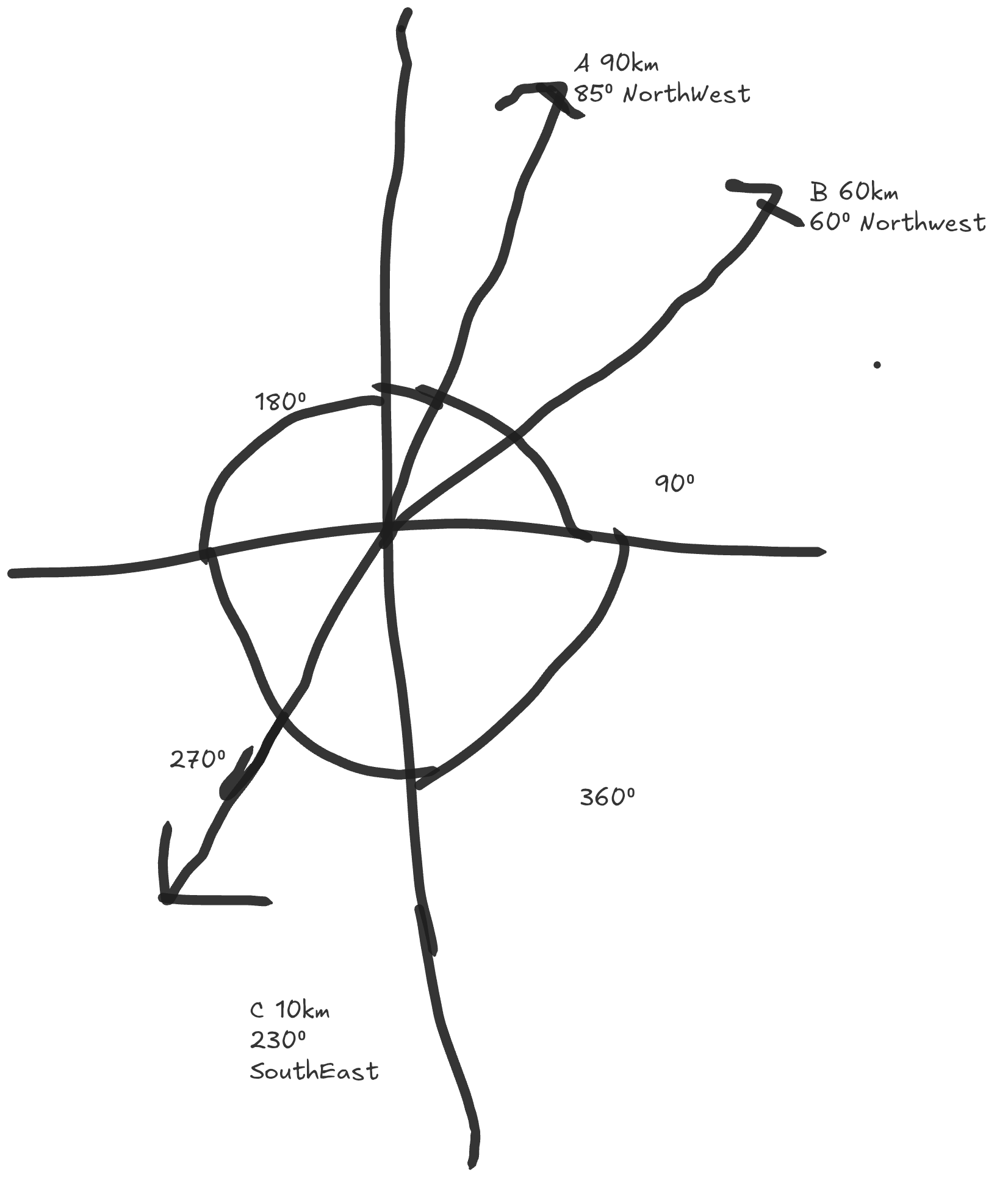
Disclaimer: I personally suck at compass navigation. Now imagine three people starting at the origin:
- Person A: Moves 90km Northwest
- Person B: Moves 60km Northwest
- Person C: Moves 10km Southeast
Even though Person C traveled the least (10km), they're actually the farthest from Person A.
Person B, who only went 60km, is closer to Person A than Person C is.
Why? Person B's direction (Northwest) is more similar to Person A's direction (Northwest) than Person C's direction (Southeast). Hence both their travel destinations did not diverge as far as Person B and Person C's.
Measuring Similarity with Angles
But the previous instruction is itself still not complete.
Northwest could be any direction between North and West; to be more precise we could add angles:
- move 90km 85° Northwest
- move 60km 60° Northwest
- move 10km 230° Southeast
How do we measure how "similar" any two directions are? We measure the angle between them.
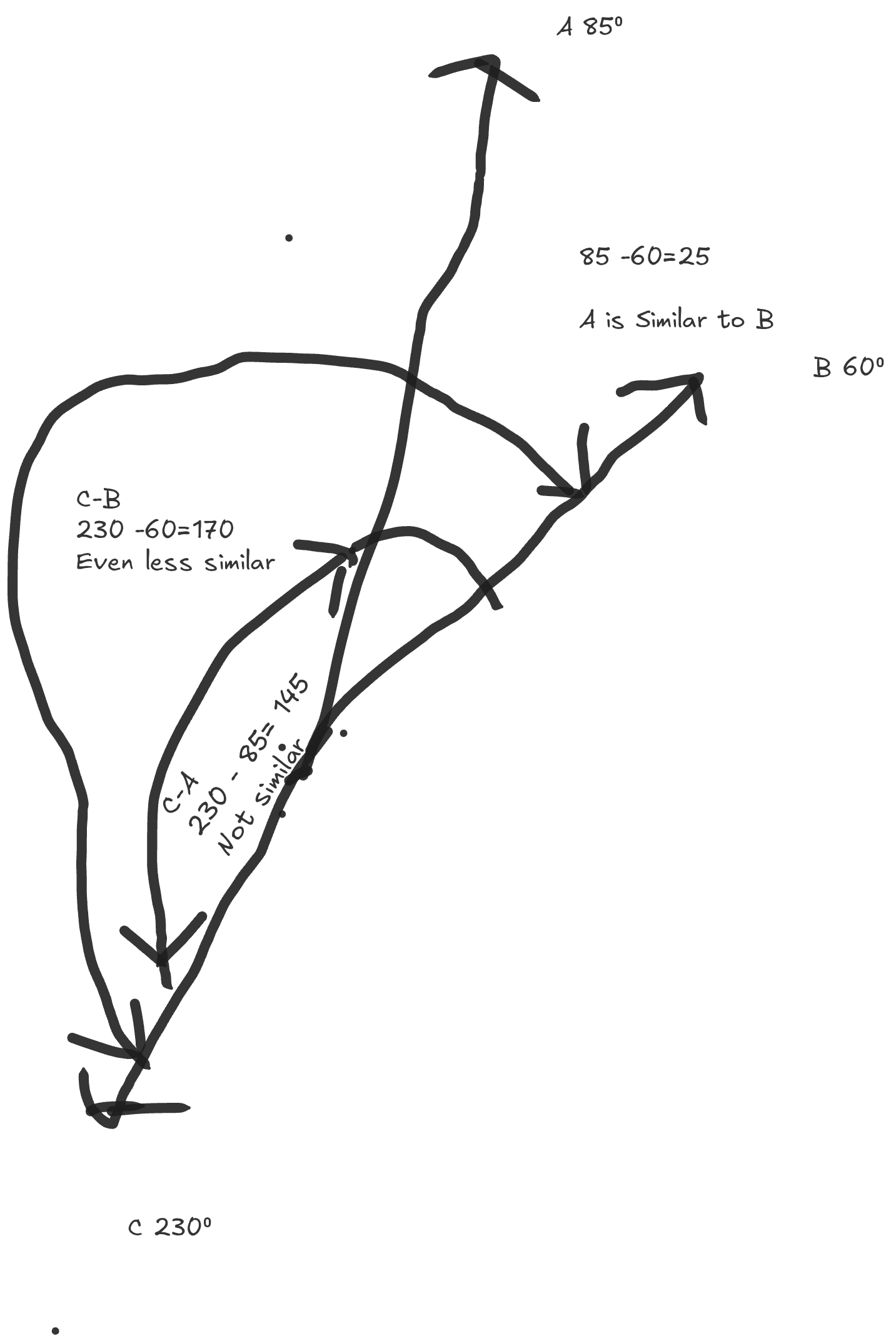
The smaller the angle, the more similar the two directions are and the lesser the divergence as we travel outwards from the origin. If we represent "I have a dog" as a vector at 40°, "My dog gave birth to a litter of five puppies" as 60°, and "Car" as 230°, we develop a system for ranking similarity. Crucially, this is magnitude-invariant. Just because "A" is a whole book about dogs doesn't change its similarity to the sentence "I have a dog," because they both point in the same "thematic" direction.
Back to Queries
Back to our cute puppy litters.
If we could represent each sentence as a vector:
- "How many pets do you have?" → Vector A (pointing in some direction)
- "How many dogs do you have?" → Vector B (pointing in a similar direction)
- "What's the weather today?" → Vector C (pointing in a completely different direction)
Then finding similar questions becomes a simple matter of:
- Converting and labeling our data as vectors
- Converting the query into a vector
- Measuring the angle between the query and all stored vectors
- Returning the ones with the smallest angles (and consequently higher similarity)
By encoding data into a mathematical representation on a vector plane, we have achieved a means of comparing data points to one another across various dimensions. But the most important measure we want here is cosine similarity.
Chapter 2
In this chapter, we will implement a basic vector search over an FAQ file.
If you're not already familiar with the concept of vector search or need a refresher, I encourage you to check out the previous chapter.
Let's get started.
Setting Up the Project
Create a new cargo project and add these to your dependencies:
reqwest = { version = "0.13.1", features=["json","native-tls"]}
rusqlite = "0.38.0"
serde = { version = "1.0.228", features = ["derive"] }
serde_json = "1.0.149"
tokio = { version = "1.49.0",features=["macros","rt-multi-thread"]}
Create a types.rs file in your src folder and add the following imports:
#![allow(unused)] fn main() { // src/types.rs use reqwest; use rusqlite::{Connection, Result as SqlResult, params}; use serde::Deserialize; use serde_json::json; use std::env; }
The Embedding Type
We need a type-safe way to represent embeddings in Rust.
#![allow(unused)] fn main() { #[derive(Debug)] pub struct Embedding { pub label: String, pub vector: Vec<f32>, } }
Generating Vectors with Embedding Models
To get our vectors, we use special models known as embedding models.
These models are trained specifically to represent text in vector format, so you can reliably reproduce the same vector for the same text.
The model we're using is gemini-embedding-001.
This model uses 768-dimensional coordinates to encode data.
First, grab your API key from Google AI Studio.
Set your Gemini API key as an environment variable:
export GEMINI_API_KEY="your_api_key_here"
Example: REST API Call
Here's an example request to the Gemini embedding model:
curl "https://generativelanguage.googleapis.com/v1beta/models/gemini-embedding-001:embedContent" \
-H "Content-Type: application/json" \
-H "x-goog-api-key: ${GEMINI_API_KEY}" \
-d '{
"model": "models/gemini-embedding-001",
"content": {
"parts": [{
"text": "What is the meaning of life?"
}]
}
}'
[!IMPORTANT] Whenever you use a model to embed data, ensure the same model is used to embed search queries.
Obviously we're not going to be working with curl.
We need (I know, I know) a type-safe way of making HTTP requests—so we're using reqwest.
#![allow(unused)] fn main() { #[derive(Deserialize)] struct GeminiResponse { embedding: EmbeddingValues, } #[derive(Deserialize)] struct BatchGeminiResponse { embeddings: Vec<EmbeddingValues>, } #[derive(Deserialize)] struct EmbeddingValues { values: Vec<f64>, } }
Now we can make calls to the API via reqwest:
#![allow(unused)] fn main() { impl Embedding { /// Create a reusable HTTP client. pub fn create_client() -> Result<reqwest::Client, reqwest::Error> { reqwest::Client::builder().build() } /// Convert a single piece of text into a vector using Gemini. pub async fn vectorize( text: &str, client: &reqwest::Client, ) -> Result<Vec<f32>, Box<dyn std::error::Error>> { let key = env::var("GEMINI_API_KEY")?; let body = json!({ "model": "models/gemini-embedding-001", "content": { "parts": [{ "text": text }] } }); let url = "https://generativelanguage.googleapis.com/v1beta/models/gemini-embedding-001:embedContent"; let res = client .post(url) .header("x-goog-api-key", &key) .json(&body) .send() .await? .json::<GeminiResponse>() .await?; Ok(res.embedding.values.into_iter().map(|v| v as f32).collect()) } } }
We now have an easy way to vectorize any given piece of text.
Let's add a way to create embeddings:
#![allow(unused)] fn main() { /// Construct a single embedding from text. pub async fn new( label: String, client: &reqwest::Client, ) -> Result<Self, Box<dyn std::error::Error>> { let vector = Self::vectorize(&label, client).await?; Ok(Self { label, vector }) } }
Next we need a database to store our embeddings:
#![allow(unused)] fn main() { /// Initialize the database schema. pub fn init_db(conn: &Connection) -> SqlResult<()> { conn.execute( "CREATE TABLE IF NOT EXISTS embeddings ( id INTEGER PRIMARY KEY, label TEXT NOT NULL UNIQUE, vector BLOB NOT NULL )", [], )?; Ok(()) } /// Persist this embedding to SQLite. /// Uses bytemuck to safely convert the f32 vector slice into bytes for storage, /// since SQLite doesn't natively support floating-point arrays. pub fn commit(&self, conn: &Connection) -> SqlResult<()> { // bytemuck::cast_slice converts &[f32] to &[u8] for binary storage let bytes: &[u8] = bytemuck::cast_slice(&self.vector); conn.execute( "INSERT OR REPLACE INTO embeddings (label, vector) VALUES (?1, ?2)", params![&self.label, bytes], )?; Ok(()) } }
We use bytemuck to cast our vectors to binary since SQLite does not support floating-point storage out of the box.
We've set up the bulk of this. We're only left with a way of comparing vectors.
The Cosine Similarity And Cosine Distance
In Chapter 1, we defined the similarity between two vectors as a measure of the angular difference between them as observed from the origin.
In practice, we use what is known as Cosine Similarity. Unlike angles which tell us where a vector is pointing relative to the x, y, or z axes — Cosine Similarity tells us how Vector A is oriented relative to Vector B.
Cosine Similarity measures the angle between any two non-zero vectors. It ranges from:
- -1 meaning opposite vectors (pointing in opposite directions)
- 0 meaning zero similarity (perpendicular vectors)
- 1 meaning identical vectors (pointing in the same direction)
The formula is described below:

The above cosine similarity of 0.8 represents a high match.
In practice however, it's more efficient to measure the gap between vectors
rather than their similarity — this is the Cosine Distance, simply 1 - similarity:
| Cosine Similarity | Cosine Distance | Meaning |
|---|---|---|
| 1 | 1 - 1 = 0 | Identical (zero distance) |
| 0 | 1 - 0 = 1 | No similarity |
| -1 | 1 - (-1) = 2 | Opposite |
This makes sorting intuitive — ascending order by distance puts the best matches first. Now we can implement it:
#![allow(unused)] fn main() { /// Compute cosine distance between two vectors. /// Returns: /// - 0.0 for identical vectors /// - 2.0 for opposite, zero, or mismatched vectors fn cosine_distance(a: &[f32], b: &[f32]) -> f32 { if a.len() != b.len() { return 2.0; } let dot: f32 = a.iter().zip(b).map(|(x, y)| x * y).sum(); let mag_a = a.iter().map(|x| x * x).sum::<f32>().sqrt(); let mag_b = b.iter().map(|x| x * x).sum::<f32>().sqrt(); if mag_a == 0.0 || mag_b == 0.0 { return 2.0; } 1.0 - dot / (mag_a * mag_b) } }
Searching with Vector Similarity
Now we can use this. We grab all embeddings in our database, compare each vector, and return the top highest matches.
Simple enough, right?
#![allow(unused)] fn main() { /// Perform a naive similarity search. /// NOTE: This performs a full table scan and is suitable only for small datasets. pub fn search(&self, conn: &Connection, limit: usize) -> SqlResult<Vec<(String, f32)>> { let mut stmt = conn.prepare("SELECT label, vector FROM embeddings")?; let mut results: Vec<(String, f32)> = stmt .query_map([], |row| { let label: String = row.get(0)?; let bytes: Vec<u8> = row.get(1)?; // bytemuck::cast_slice converts &[u8] back to &[f32] for computation let stored: &[f32] = bytemuck::cast_slice(&bytes); let distance = Self::cosine_distance(&self.vector, stored); Ok((label, distance)) })? .collect::<Result<_, _>>()?; results.sort_by(|a, b| a.1.partial_cmp(&b.1).unwrap()); results.truncate(limit); Ok(results) } }
We've gotten all the working parts ready!
Now let's slot it all in a CLI interface and see what we have:
// main.rs pub mod types; use crate::types::Embedding; use rusqlite::Connection; use std::fs::File; use std::io::{self, BufRead, BufReader, Write}; #[tokio::main] async fn main() -> Result<(), Box<dyn std::error::Error>> { let conn = Connection::open("./embeddings.db")?; let client = Embedding::create_client()?; Embedding::init_db(&conn)?; println!("=== FAQ Search System ==="); println!("Commands:"); println!(" search <query> - Search for similar questions"); println!(" load - Load FAQ from faq.txt"); println!(" optimize - Optimize vector index for faster search"); println!(" quit - Exit program"); println!(); loop { print!("> "); io::stdout().flush()?; let mut input = String::new(); io::stdin().read_line(&mut input)?; let input = input.trim(); if input.is_empty() { continue; } let parts: Vec<&str> = input.splitn(2, ' ').collect(); let command = parts[0]; match command { "quit" | "exit" | "q" => { println!("Goodbye!"); break; } "load" => { println!("Loading FAQ..."); load_faq(&client, &conn).await?; println!("✓ FAQ loaded successfully!"); println!(" Tip: Run 'optimize' to speed up searches"); } "optimize" => { println!("Optimizing vector index..."); // stub println!("✓ Optimization complete (placeholder)"); } "search" => { if parts.len() < 2 { println!("Usage: search <your question>"); continue; } let query = parts[1].trim_matches('"').trim(); search_faq(query, &client, &conn).await?; } _ => { search_faq(input, &client, &conn).await?; } } } Ok(()) } async fn search_faq( query: &str, client: &reqwest::Client, conn: &Connection, ) -> Result<(), Box<dyn std::error::Error>> { println!("\nSearching for: \"{}\"", query); println!("Generating embedding..."); let query_embedding = Embedding::new(query.to_string(), client).await?; let results = query_embedding.search(conn, 3)?; if results.is_empty() { println!("No results found. Try loading the FAQ first with 'load' command."); return Ok(()); } println!("\n--- Top {} Results ---", results.len()); for (i, (label, distance)) in results.iter().enumerate() { let similarity = 1.0 - distance; println!("\n{}. [Similarity: {:.2}%]", i + 1, similarity * 100.0); println!(" {}", label); if similarity > 0.7 { println!(" ✓ Strong match!"); } } println!(); Ok(()) } async fn load_faq( client: &reqwest::Client, conn: &Connection, ) -> Result<(), Box<dyn std::error::Error>> { let file = File::open("faq.txt")?; let reader = BufReader::new(file); let mut current_question = String::new(); let mut current_answer = String::new(); let mut count = 0; for line in reader.lines() { let line = line?; let trimmed = line.trim(); if trimmed.is_empty() || trimmed.starts_with("===") { continue; } if trimmed.starts_with("Q: ") { if !current_question.is_empty() && !current_answer.is_empty() { let combined = format!("Q: {}\nA: {}", current_question, current_answer); let embedding = Embedding::new(combined, client).await?; embedding.commit(conn)?; count += 1; print!("\rEmbedded {} questions...", count); io::stdout().flush()?; } current_question = trimmed.strip_prefix("Q: ").unwrap().to_string(); current_answer.clear(); } else if trimmed.starts_with("A: ") { current_answer = trimmed.strip_prefix("A: ").unwrap().to_string(); } else if !current_answer.is_empty() { current_answer.push('\n'); current_answer.push_str(trimmed); } } if !current_question.is_empty() && !current_answer.is_empty() { let combined = format!("Q: {}\nA: {}", current_question, current_answer); let embedding = Embedding::new(combined, client).await?; embedding.commit(conn)?; count += 1; } println!("\n✓ Total embedded: {} Q&A pairs", count); Ok(()) }
Putting It Together
Your faq.txt should follow this format:
Q: What services do you offer?
A: I specialize in automation and bot development.
Q: Which languages do you use?
A: Primarily Rust and Go for performance-critical work.
Load it with load, then try a search:
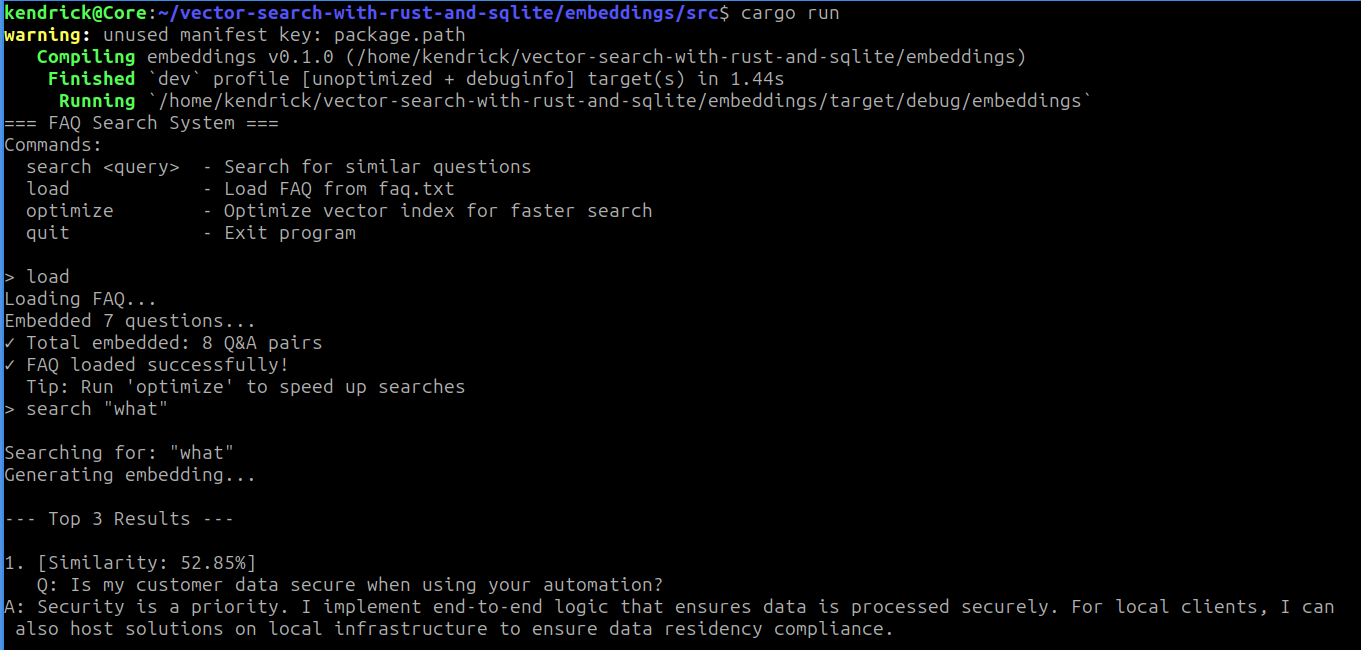
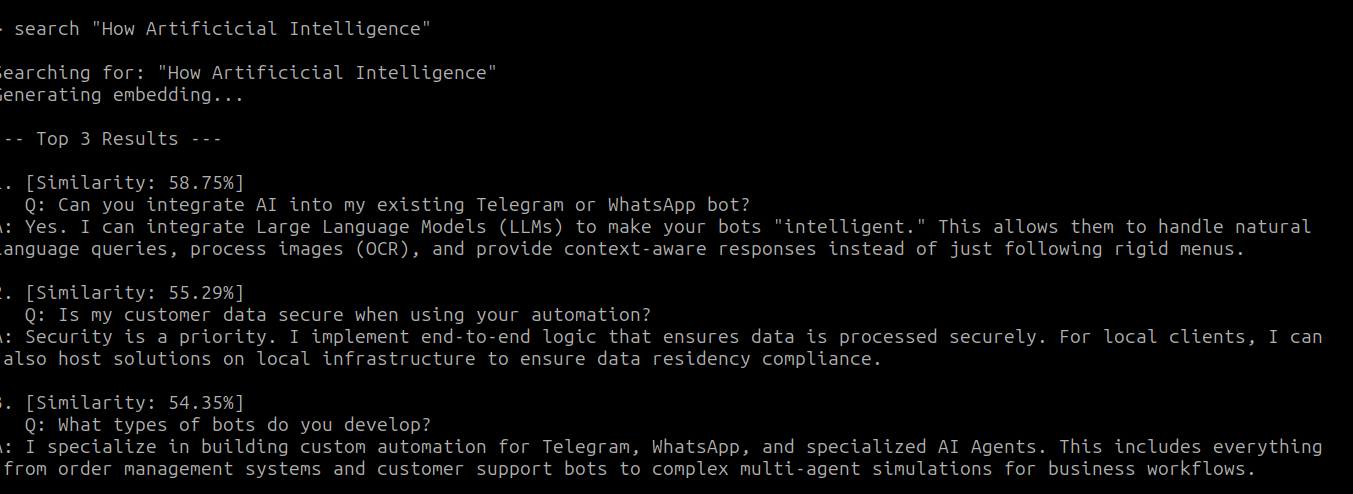
Those are my output! How about Yours?
While we've come a long way, there's still work to be done — our program is rough around the edges. With no error handling, if anything goes wrong (and I assure you it will) we have no idea where, or we crash completely. Many of our variables are also hardcoded — the database file, the FAQ file, the number of search results. We'll fix all of that in the next chapter.
Refactoring
In the last chapter we managed to cobble up something working from scratch, but it's not enough to just work — we must make it better.
In this chapter, we're going to poke some holes in our previous setup and look at how we can make it more secure and robust.
Let's start with error handling. As of now, every little error crashes our program and the error messages returned are quite vague.
We used
#![allow(unused)] fn main() { Result<T, Box<dyn std::error::Error>> }
to propagate errors upwards from each of our functions. This is convenient, but it collapses every error into one generic, vague type which offers little information. For example, if we have a missing API key in our environment variables, the program exits with a generic error message as shown below:
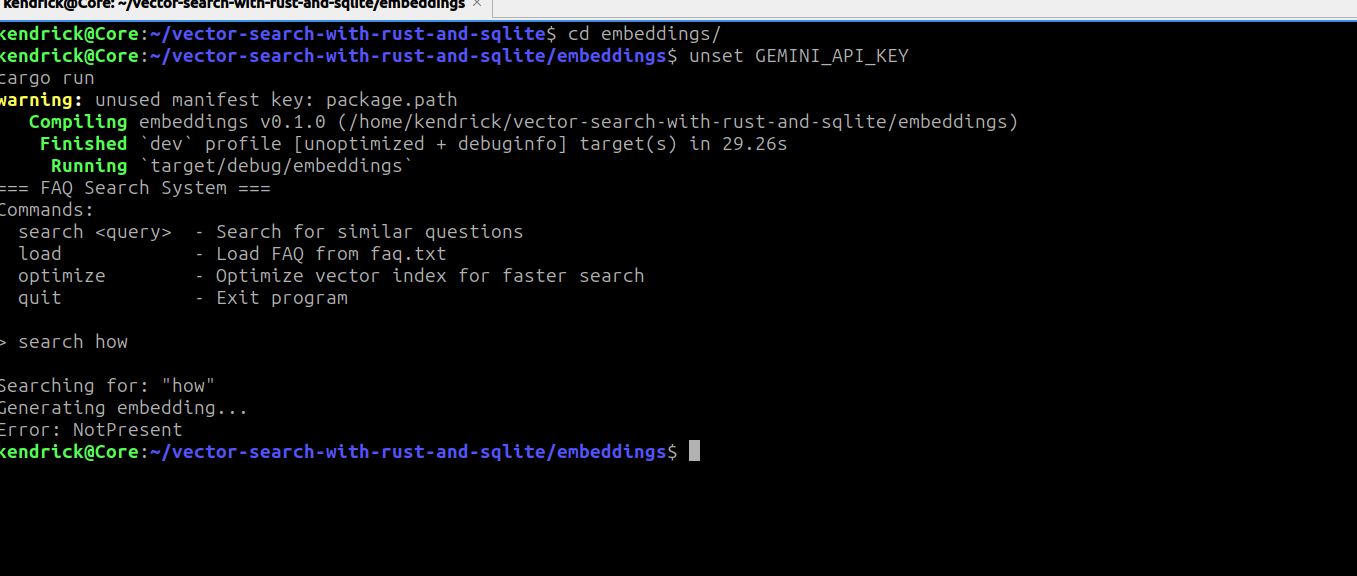
Looking at our setup we can identify several distinct boundaries which might fail:
- IO — reading the FAQ might fail due to a missing file or missing permissions
- Network — to transform each of our texts to vectors we make an HTTP request to the Gemini API
- Database — database operations might fail due to a missing database or missing permissions
- Env — our API key for Gemini is read from environment variables
- Parse — the FAQ file or Gemini API response might not match the expected format
To make our program better we need to provide explicit error messages at each of these boundaries. We do this by defining a custom error type:
#![allow(unused)] fn main() { use std::{fmt::Display, io}; #[derive(Debug)] pub enum AppError { IOError(std::io::Error), NetworkError(reqwest::Error), DBError(rusqlite::Error), EnvError(std::env::VarError), ParseError(String), DimensionMismatch { expected: usize, got: usize }, ZeroVector } impl Display for AppError { fn fmt(&self, f: &mut std::fmt::Formatter<'_>) -> std::fmt::Result { match self { AppError::IOError(e) => match e.kind() { io::ErrorKind::NotFound => write!(f, "File not found"), io::ErrorKind::PermissionDenied => write!(f, "Permission denied"), _ => write!(f, "IO error: {e}"), }, AppError::NetworkError(e) => match e.status() { Some(status) => match status { reqwest::StatusCode::UNAUTHORIZED => write!(f, "Invalid API key"), reqwest::StatusCode::TOO_MANY_REQUESTS => write!(f, "Rate limit exceeded"), reqwest::StatusCode::NOT_FOUND => write!(f, "API endpoint not found"), reqwest::StatusCode::INTERNAL_SERVER_ERROR => write!(f, "Gemini API error"), _ => write!(f, "Network error: {e}"), }, None => { if e.is_timeout() { write!(f, "Request timed out") } else if e.is_connect() { write!(f, "Connection failed") } else { write!(f, "Network error: {e}") } } }, AppError::DBError(e) => write!(f, "Database error: {e}"), AppError::EnvError(e) => write!(f, "Missing environment variable: {e}"), AppError::ParseError(e) => write!(f, "Parse error: {e}"), AppError::DimensionMismatch { expected, got } => { write!(f, "Vector dimension mismatch: expected {expected}, got {got}") }, AppError::ZeroVector => write!(f, "Cannot compute similarity for a zero vector"), } } } impl std::error::Error for AppError {} macro_rules! impl_from { ($variant:ident, $error:ty) => { impl From<$error> for AppError { fn from(e: $error) -> Self { Self::$variant(e) } } }; } impl_from!(IOError, io::Error); impl_from!(NetworkError, reqwest::Error); impl_from!(DBError, rusqlite::Error); impl_from!(EnvError, std::env::VarError); impl_from!(ParseError, String); }
We explicitly define an enum whose variants each wrap a specific error type,
giving us precise information about what went wrong and where. The impl_from!
macro derives From trait implementations for each variant, allowing the ?
operator to automatically convert errors into the appropriate AppError variant
without any manual casting.
What's left is to replace every Box<dyn std::error::Error> in our codebase
with AppError. We also take this opportunity to move our embedding logic into
lib.rs, separating it from the entry point:
#![allow(unused)] fn main() { // src/types.rs use reqwest; use rusqlite::{Connection, params}; use serde::Deserialize; use serde_json::json; use std::env; use crate::errors::AppError; #[derive(Debug)] pub struct Embedding { pub label: String, pub vector: Vec<f32>, } #[derive(Deserialize)] struct GeminiResponse { embedding: EmbeddingValues, } #[derive(Deserialize)] struct BatchGeminiResponse { embeddings: Vec<EmbeddingValues>, } #[derive(Deserialize)] struct EmbeddingValues { values: Vec<f64>, } impl Embedding { /// Compute cosine distance between two vectors. fn cosine_distance(a: &[f32], b: &[f32]) -> Result<f32, AppError> { if a.len() != b.len() { return Err(AppError::DimensionMismatch { expected: a.len(), got: b.len(), }); } let dot: f32 = a.iter().zip(b).map(|(x, y)| x * y).sum(); let mag_a = a.iter().map(|x| x * x).sum::<f32>().sqrt(); let mag_b = b.iter().map(|x| x * x).sum::<f32>().sqrt(); if mag_a == 0.0 || mag_b == 0.0 { return Err(AppError::ZeroVector); } Ok(1.0 - dot / (mag_a * mag_b)) } /// Initialize the database schema. pub fn init_db(conn: &Connection) -> Result<(), AppError> { conn.execute( "CREATE TABLE IF NOT EXISTS embeddings ( id INTEGER PRIMARY KEY, label TEXT NOT NULL UNIQUE, vector BLOB NOT NULL )", [], )?; Ok(()) } /// Persist this embedding to SQLite. pub fn commit(&self, conn: &Connection) -> Result<(), AppError> { let bytes: &[u8] = bytemuck::cast_slice(&self.vector); conn.execute( "INSERT OR REPLACE INTO embeddings (label, vector) VALUES (?1, ?2)", params![&self.label, bytes], )?; Ok(()) } /// Perform a naive similarity search. /// NOTE: This performs a full table scan and is suitable only for small datasets. pub fn search(&self, conn: &Connection, limit: usize) -> Result<Vec<(String, f32)>, AppError> { let mut stmt = conn.prepare("SELECT label, vector FROM embeddings")?; let mut results: Vec<(String, f32)> = stmt .query_map([], |row| { let label: String = row.get(0)?; let bytes: Vec<u8> = row.get(1)?; let stored: &[f32] = bytemuck::cast_slice(&bytes); // cosine_distance can't use ? inside query_map's closure since // it expects rusqlite::Error — map to a sentinel and surface // the real error after collection let distance = Self::cosine_distance(&self.vector, stored).unwrap_or(2.0); Ok((label, distance)) })? .collect::<Result<_, _>>()?; results.sort_by(|a, b| a.1.partial_cmp(&b.1).unwrap()); results.truncate(limit); Ok(results) } /// Create a reusable HTTP client. pub fn create_client() -> Result<reqwest::Client, AppError> { Ok(reqwest::Client::builder().build()?) } /// Convert a single piece of text into a vector using Gemini. pub async fn vectorize( text: &str, client: &reqwest::Client, ) -> Result<Vec<f32>, AppError> { let key = env::var("GEMINI_API_KEY")?; let body = json!({ "model": "models/gemini-embedding-001", "content": { "parts": [{ "text": text }] } }); let url = "https://generativelanguage.googleapis.com/v1beta/models/gemini-embedding-001:embedContent"; let res = client .post(url) .header("x-goog-api-key", &key) .json(&body) .send() .await? .json::<GeminiResponse>() .await?; Ok(res.embedding.values.into_iter().map(|v| v as f32).collect()) } /// Convert multiple texts into vectors using Gemini batch embedding. pub async fn batch_vectorize( texts: &[String], client: &reqwest::Client, ) -> Result<Vec<Vec<f32>>, AppError> { let key = env::var("GEMINI_API_KEY")?; let requests: Vec<_> = texts .iter() .map(|text| { json!({ "model": "models/gemini-embedding-001", "content": { "parts": [{ "text": text }] } }) }) .collect(); let body = json!({ "requests": requests }); let url = "https://generativelanguage.googleapis.com/v1beta/models/gemini-embedding-001:batchEmbedContents"; let res = client .post(url) .header("x-goog-api-key", &key) .json(&body) .send() .await? .json::<BatchGeminiResponse>() .await?; Ok(res .embeddings .into_iter() .map(|e| e.values.into_iter().map(|v| v as f32).collect()) .collect()) } /// Construct a single embedding from text. pub async fn new( label: String, client: &reqwest::Client, ) -> Result<Self, AppError> { let vector = Self::vectorize(&label, client).await?; Ok(Self { label, vector }) } /// Construct multiple embeddings from text using batch vectorization. pub async fn batch_new( labels: Vec<String>, client: &reqwest::Client, ) -> Result<Vec<Self>, AppError> { let vectors = Self::batch_vectorize(&labels, client).await?; Ok(labels .into_iter() .zip(vectors) .map(|(label, vector)| Embedding { label, vector }) .collect()) } } }
#![allow(unused)] fn main() { use crate::errors::AppError; pub mod errors; pub mod types; use crate::types::{Embedding}; use rusqlite::Connection; use std::fs::File; use std::io::{self, BufRead, BufReader, Write}; async fn search_faq( query: &str, client: &reqwest::Client, conn: &Connection, ) -> Result<(), AppError> { println!("\nSearching for: \"{}\"", query); println!("Generating embedding..."); let query_embedding = Embedding::new(query.to_string(), client).await?; let results = query_embedding.search(conn, 3)?; if results.is_empty() { println!("No results found. Try loading the FAQ first with 'load' command."); return Ok(()); } println!("\n--- Top {} Results ---", results.len()); for (i, (label, distance)) in results.iter().enumerate() { let similarity = 1.0 - distance; println!("\n{}. [Similarity: {:.2}%]", i + 1, similarity * 100.0); println!(" {}", label); if similarity > 0.7 { println!(" ✓ Strong match!"); } } println!(); Ok(()) } async fn load_faq( client: &reqwest::Client, conn: &Connection, ) -> Result<(), AppError> { let file = File::open("./faq.txt")?; let reader = BufReader::new(file); let mut current_question = String::new(); let mut current_answer = String::new(); let mut count = 0; for line in reader.lines() { let line = line.map_err(|e|AppError::ParseError(e.to_string()))?; let trimmed = line.trim(); if trimmed.is_empty() || trimmed.starts_with("===") { continue; } if trimmed.starts_with("Q: ") { if !current_question.is_empty() && !current_answer.is_empty() { let combined = format!("Q: {}\nA: {}", current_question, current_answer); let embedding = Embedding::new(combined, client).await?; embedding.commit(conn)?; count += 1; print!("\rEmbedded {} questions...", count); io::stdout().flush()?; } current_question = trimmed.strip_prefix("Q: ").unwrap().to_string(); current_answer.clear(); } else if trimmed.starts_with("A: ") { current_answer = trimmed.strip_prefix("A: ").unwrap().to_string(); } else if !current_answer.is_empty() { current_answer.push('\n'); current_answer.push_str(trimmed); } } if !current_question.is_empty() && !current_answer.is_empty() { let combined = format!("Q: {}\nA: {}", current_question, current_answer); let embedding = Embedding::new(combined, client).await?; embedding.commit(conn)?; count += 1; } println!("\n✓ Total embedded: {} Q&A pairs", count); Ok(()) } pub async fn run()->Result<(),AppError>{ let conn = Connection::open("./embeddings.db")?; let client = Embedding::create_client()?; Embedding::init_db(&conn)?; println!("=== FAQ Search System ==="); println!("Commands:"); println!(" search <query> - Search for similar questions"); println!(" load - Load FAQ from faq.txt"); println!(" optimize - Optimize vector index for faster search"); println!(" quit - Exit program"); println!(); loop { print!("> "); io::stdout().flush()?; let mut input = String::new(); io::stdin().read_line(&mut input)?; let input = input.trim(); if input.is_empty() { continue; } let parts: Vec<&str> = input.splitn(2, ' ').collect(); let command = parts[0]; match command { "quit" | "exit" | "q" => { println!("Goodbye!"); break; } "load" => { println!("Loading FAQ..."); load_faq(&client, &conn).await?; println!("✓ FAQ loaded successfully!"); println!(" Tip: Run 'optimize' to speed up searches"); } "optimize" => { println!("Optimizing vector index..."); println!("✓ Optimization complete (placeholder)"); } "search" => { if parts.len() < 2 { println!("Usage: search <your question>"); continue; } let query = parts[1].trim_matches('"').trim(); search_faq(query, &client, &conn).await?; } _ => { search_faq(input, &client, &conn).await?; } } } Ok(()) } }
main.rs is now responsible for one thing — running the program and surfacing
any errors to the user via Display, rather than letting Rust's default Debug
output bypass our custom messages:
// main.rs use embeddings::run; #[tokio::main] async fn main() { if let Err(e) = run().await { eprintln!("{}",e); std::process::exit(1) } }